|
I work on problems in graphics and 3D computer vision at World Labs. From 2021 to 2023, I was a research scientist at Google Research. I received my PhD from UC Berkeley in 2020, where I was advised by Ren Ng and supported by a Hertz fellowship. In the summer of 2017, I was an intern in Marc Levoy's group in Google Research. In the summer of 2018, I worked with Rodrigo Ortiz-Cayon and Abhishek Kar at Fyusion. I did my undergrad at Stanford University and worked at Pixar Research in the summer of 2014. |

|
|
|
Many images to 3D
Bigger and better NeRF
Text to 3D
Few images to 3D
|
|

|
Dor Verbin, Pratul Srinivasan, Peter Hedman, Benjamin Attal, Ben Mildenhall, Richard Szeliski, Jonathan T. Barron SIGGRAPH Asia, 2024 project page / arXiv Carefully casting reflection rays lets us synthesize photorealistic specularities in real-world scenes. |

|
Benjamin Attal, Dor Verbin, Ben Mildenhall, Peter Hedman, Jonathan T. Barron, Matthew O'Toole, Pratul P. Srinivasan ECCV, 2024 (oral) project page / arXiv Radiance caching enables more physically accurate inverse rendering to recover geometry, materials, and lighting from RGB images of an object or scene. |

|
Pratul Srinivasan, Stephan J. Garbin, Dor Verbin, Jonathan T. Barron, Ben Mildenhall ECCV, 2024 project page / video / arXiv Use neural fields to recover editable UV mappings for challenging geometry (e.g. NeRFs, marching cubes meshes, DreamFusion). |

|
Christian Reiser, Stephan J. Garbin, Pratul Srinivasan, Dor Verbin, Richard Szeliski, Ben Mildenhall, Jonathan T. Barron, Peter Hedman*, Andreas Geiger* SIGGRAPH, 2024 project page / video / arXiv Apply anti-aliasing to a discrete opacity grid to enable highly-detailed mesh recovery. |

|
Rundi Wu*, Ben Mildenhall*, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul Srinivasan, Dor Verbin, Jonathan T. Barron, Ben Poole, Aleksander Holynski* CVPR, 2024 project page / arXiv Finetune an image diffusion model to accept multiview inputs, then use it to regularize radiance field reconstruction. |

|
Dor Verbin, Ben Mildenhall, Peter Hedman, Jonathan T. Barron, Todd Zickler, Pratul Srinivasan CVPR, 2024 (oral) project page / video / arXiv Shadows cast by unobserved occluders provide a high-frequency cue for recovering illumination and materials. |

|
Xiaojuan Wang, Janne Kontkanen, Brian Curless, Steve Seitz, Ira Kemelmacher, Ben Mildenhall, Pratul Srinivasan, Dor Verbin, Aleksander Holynski CVPR, 2024 (highlight) project page / arXiv Use a text-to-image model to generate consistent content across drastically varying scales. |
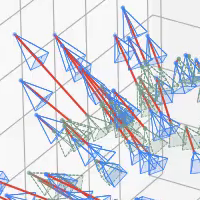
|
Keunhong Park, Philipp Henzler, Ben Mildenhall, Jonathan T. Barron, Ricardo Martin-Brualla SIGGRAPH Asia, 2023 project page / arXiv Preconditioning based on camera parameterization helps NeRF and camera extrinsics/intrinsics optimize better together. |

|
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul Srinivasan, Peter Hedman ICCV, 2023 (Best Paper Finalist) project page / video / arXiv Combining mip-NeRF 360 and Instant NGP lets us reconstruct huge scenes. |

|
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan T. Barron, Yuanzhen Li, Varun Jampani ICCV, 2023 project page / arXiv Combining DreamBooth (personalized text-to-image) and DreamFusion (text-to-3D) yields high-quality, subject-specific 3D assets with text-driven modifications |

|
Lior Yariv*, Peter Hedman*, Christian Reiser, Dor Verbin, Pratul Srinivasan, Richard Szeliski, Jonathan T. Barron, Ben Mildenhall SIGGRAPH, 2023 project page / video / arXiv We achieve real-time view synthesis by baking a high quality mesh and fine-tuning a lightweight appearance model on top. |
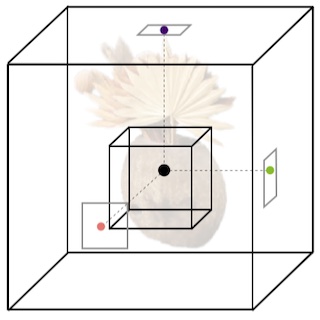
|
Christian Reiser, Richard Szeliski, Dor Verbin, Pratul Srinivasan, Ben Mildenhall, Andreas Geiger, Jonathan T. Barron, Peter Hedman SIGGRAPH, 2023 project page / video / arXiv We achieve real-time view synthesis using a volumetric rendering model with a compact representation combining a sparse 3D feature grid and 2D feature planes. |
 
|
Yifan Jiang, Peter Hedman, Ben Mildenhall, Dejia Xu, Jonathan T. Barron, Zhangyang Wang, Tianfan Xue CVPR, 2023 project page / arXiv Accounting for misalignment due to scene motion or calibration errors improves NeRF reconstruction quality. |

|
Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall ICLR, 2023 (Outstanding Paper Award) project page / arXiv / gallery We optimize a NeRF from scratch using a pretrained text-to-image diffusion model to do text-to-3D generative modeling. |
 
|
Yifan Jiang, Bartlomiej Wronski, Ben Mildenhall, Jonathan T. Barron, Zhangyang Wang, Tianfan Xue ECCV, 2022 project page / arXiv We denoise images efficiently by predicting spatially-varying kernels at low resolution and using a fast fused op to jointly upsample and apply these kernels at full resolution. |

|
Ben Mildenhall, Peter Hedman, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan Barron CVPR, 2022 (oral) project page / arXiv / video / code We train RawNeRF directly on linear raw camera images, enabling new HDR view synthesis applications and greatly increasing robustness to camera noise. |

|
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul Srinivasan, Peter Hedman CVPR, 2022 (oral) project page / arXiv / video / code We extend mip-NeRF to produce photorealistic results on unbounded scenes. |

|
Dor Verbin, Peter Hedman, Ben Mildenhall, Todd Zickler, Jonathan T. Barron, Pratul Srinivasan CVPR, 2022 (Best Student Paper Honorable Mention) project page / arXiv / video / code Explicitly modeling reflections in NeRF produces realistic shiny surfaces and accurate surface normals, and lets you edit materials. |

|
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul Srinivasan, Jonathan T. Barron, Henrik Kretzschmar CVPR, 2022 (oral) project page / arXiv / video We build city-scale scenes from many NeRFs, trained using millions of images. |

|
Michael Niemeyer, Jonathan T. Barron, Ben Mildenhall, Mehdi S. M. Sajjadi, Andreas Geiger, Noha Radwan CVPR, 2022 (oral) project page / arXiv / video We regularize unseen views during optimization to enable view synthesis from as few as 3 input images. |

|
Ajay Jain, Ben Mildenhall, Jonathan T. Barron, Pieter Abbeel, Ben Poole CVPR, 2022 project page / arXiv / video / code Supervising the CLIP embeddings of NeRF renderings allows us to generate 3D objects from text prompts alone. |
 
|
Barbara Roessle, Jonathan T. Barron, Ben Mildenhall, Pratul Srinivasan, Matthias Nießner CVPR, 2022 arXiv / video We apply dense depth completion techniques to freely-available sparse stereo data to guide NeRF reconstructions from few input images. |
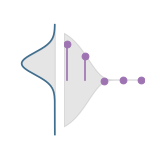
|
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, Pratul Srinivasan ICCV, 2021 (Best Paper Honorable Mention) project page / arXiv / video / code We prefilter the positional encoding function and train NeRF to generate anti-aliased renderings. |

|
Peter Hedman, Pratul Srinivasan, Ben Mildenhall, Jonathan T. Barron, Paul Debevec ICCV, 2021 (oral) project page / arXiv / video / demo We bake a trained NeRF into a sparse voxel grid of colors and features in order to render it in real-time. |

|
Matthew Tancik*, Ben Mildenhall*, Terrance Wang, Divi Schmidt, Pratul Srinivasan, Jonathan T. Barron, Ren Ng CVPR, 2021 (oral) project page / arXiv / video / code We use meta-learning to find weight initializations for coordinate-based MLPs that allow them to converge faster and generalize better. |

|
Pratul Srinivasan, Boyang Deng, Xiuming Zhang, Matthew Tancik, Ben Mildenhall, Jonathan T. Barron CVPR, 2021 project page / arXiv / video We recover relightable NeRF-like models using neural approximations of expensive visibility integrals, so we can simulate complex volumetric light transport during training. |
 
|
Matthew Tancik*, Pratul Srinivasan*, Ben Mildenhall*, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, Ren Ng NeurIPS, 2020 (spotlight) project page / arXiv / code We demonstrate that composing fully-connected networks with a simple Fourier feature mapping allows them to learn much high frequency functions. |

|
Sai Bi*, Zexiang Xu*, Pratul Srinivasan, Ben Mildenhall, Kalyan Sunkavalli, Milos Hasan, Yannick Hold-Geoffroy, David Kriegman, Ravi Ramamoorthi arXiv, 2020 arXiv We recover relightable NeRF-like models by predicting per-location BRDFs and surface normals, and marching light rays through the NeRV volume to compute visibility. |

|
Ben Mildenhall*, Pratul Srinivasan*, Matthew Tancik*, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng ECCV, 2020 (Best Paper Honorable Mention) project page / arXiv / video / talk / code / two minute papers / papers with code / wired We optimize a simple fully-connected network to represent a single scene as a volume, then use volume rendering to do view synthesis. |

|
Kai-En Lin, Zexiang Xu, Ben Mildenhall, Pratul Srinivasan, Yannick Hold-Geoffroy, Stephen DiVerdi, Qi Sun, Kalyan Sunkavalli, Ravi Ramamoorthi ECCV, 2020 arXiv / video We represent scenes as multi-layer panoramas with depth for VR view synthesis. |
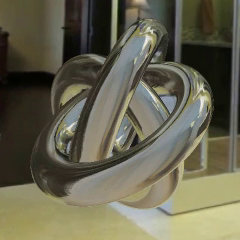
|
Pratul Srinivasan*, Ben Mildenhall*, Matthew Tancik, Jonathan T. Barron, Richard Tucker, Noah Snavely CVPR, 2020 project page / arXiv / video / code We predict a volume from an input stereo pair that can be used to calculate incident lighting at any 3D point within a scene. |

|
Matthew Tancik*, Ben Mildenhall*, Ren Ng CVPR, 2020 project page / arXiv / video / code We can hide hyperlinks in natural images to create aesthetically pleasing barcodes. |

|
Ben Mildenhall*, Pratul Srinivasan*, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, Abhishek Kar SIGGRAPH, 2019 project page / arXiv / video / code We develop and analyze a deep learning method for rendering novel views of complex real world scenes. |
 
|
Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, Jonathan T. Barron CVPR, 2019 (oral) project page / arXiv We can learn a better denoising model by processing and unprocessing images the same way a camera does. |
 
|
We train a network to predict linear kernels that denoise bursts of raw linear images. |
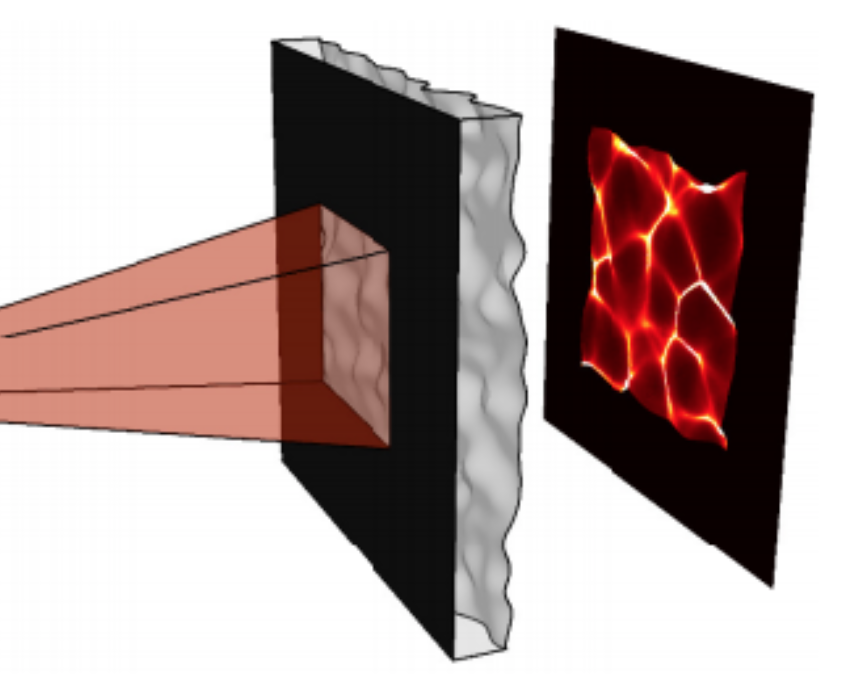 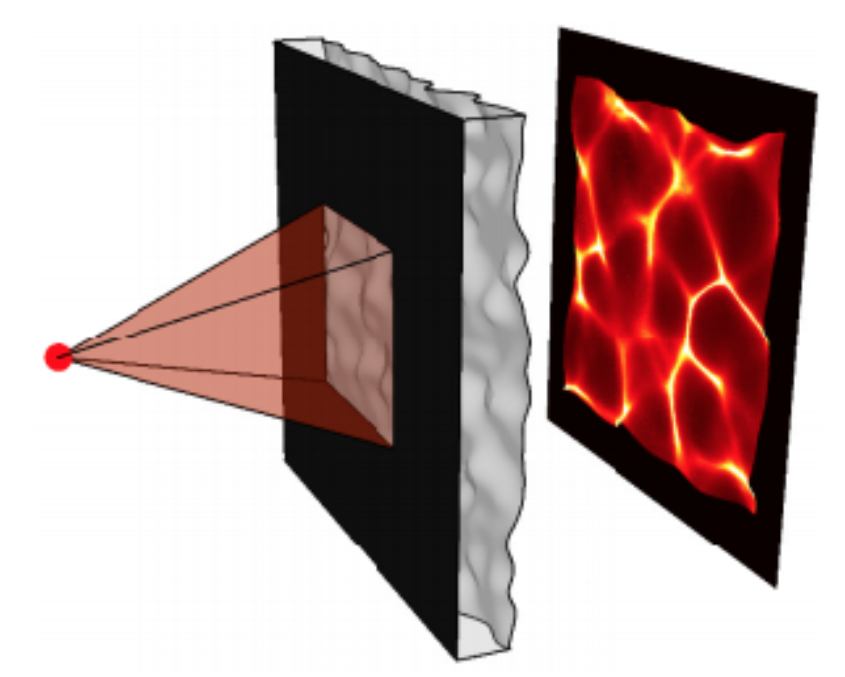
|
Using a diffuser instead of a lens lets you recover 3D in a single exposure. |
 |
We precompute microflake approximations to make rendering large meshes at a distance more efficient. |
 |
We improve control over the output of highly-variable procedural modeling programs by using SOSMC to provide incremental feedback on partially-generated models. |
|
|
 |
Adding support for multicolored, nonhomogeneous, emissive volumes in PBRT 2's path tracing integrator. |
 |
Implemented a ray tracer with reflections, refractions, soft shadows, and depth of field. |
|
|
 |
|
|
|
 |
|
|
Yep it's another Jon Barron website. |